

OpenClaw Architecture - Part 3: Memory and State Ownership
Why “memory” isn’t learning… and why it’s really just state + rehydration


This is Part 3 of a multi-part OpenClaw architecture series by Vinoth Govindarajan. I’ll publish the canonical, series-linked version on The Agent Stack shortly. If you want the full index + future parts, subscribe there.
Two days later, your agent schedules a meeting exactly when you told it your kid’s school pickup time was.
The failure mode isn’t “it forgot the capital of France.”
It’s: it acknowledged a durable constraint, and then acted like it never happened.
Not because the model is dumb.
Because nothing durable got written, and the rehydration path had nothing to load.
Thesis: Agent “memory” isn’t model learning. It’s state ownership + rehydration. The interesting work is deciding what survives, where it lives, who’s allowed to write it, and how it gets injected back into the hot path without blowing up latency, cost, or safety.
My take: “Memory” isn’t a feature. It’s a contract: state must have an owner, a durable home, and a rehydration path.
1) Sessions vs memory: two different stores
You need two stores because they optimize for different things:
Session = the working set for this conversation (hot path).
Memory = durable state that survives across sessions (cold path that gets rehydrated selectively).
If you don’t separate them, you end up treating “whatever is still in the transcript” as “truth.” That’s how you get drift.
Inside Out as a mental model (with one important caveat)
Pixar’s Inside Out gets one architecture point exactly right: memory has two lifespans.
Working memory is what’s “in mind” right now (what the movie calls Headquarters).
Long‑term memory is what survives when the working set can’t hold everything (the shelves in Long Term).
That maps cleanly to agents:
Session = Headquarters (hot, messy, constantly changing).
Memory = Long Term (durable state you can rehydrate later).
But the most useful lesson from the science angle is the caveat: recall is not a perfect replay.
The movie shows a memory orb being “projected” back in Headquarters. In cognitive science, recall is often described as reconstructive: fragments get reassembled, and the act of recalling can modify what gets stored next time. That’s the agent version of “memory drift.”
In other words: retrieval doesn’t hand you truth. It hands you evidence. The runtime then synthesizes an answer, and if you’re not careful, it will also synthesize a new memory that overwrites the old one.
My take: this is why “memory” needs state ownership + write policies. If recall is reconstructive, then durable writes are a privileged operation, not a convenience feature.
2) State ownership: pick a durable source of truth
Most “my agent forgot” incidents are ownership failures:
the system didn’t decide where a fact belongs,
or it wrote it somewhere “kind of durable,”
or it wrote it in five places and retrieval became nondeterministic.
OpenClaw makes a very opinionated choice: memory is plain Markdown in the agent workspace. Files are the source of truth; the model only “remembers” what gets written to disk.
This is explicitly reflected in the OpenClaw memory model and tooling (memory_search, memory_get) and how memory is stored in the workspace.
OpenClaw’s default layout encodes ownership:
memory/YYYY-MM-DD.md: daily, append-only logMEMORY.md(optional): curated long-term memory
Two practical notes that help avoid over-claiming:
By default,
MEMORY.mdis scoped to the main/private session to reduce group-context leakage.Daily logs can be messy and high-volume. Curated memory needs to stay small and high-signal, because it will be consulted forever.
3) The key invariant: flush before we discard context
Part 2’s signature invariant was about concurrency:
single-writer per session lane.
Part 3’s signature invariant is about time:
Invariant: before we discard context, we must first persist whatever must survive.
This is the 3:00 AM moment for memory systems: compaction did its job, the session kept moving… and the one decision you needed later never made it to durable state.
OpenClaw implements this as a pre-compaction memory flush: as a session approaches compaction, it runs a silent turn that nudges the model to write durable notes before older context is compacted away.
This behavior is controlled via agents.defaults.compaction.memoryFlush and the associated flush prompt/config.
Two details are easy to gloss over, but matter in production:
The flush is designed to be silent. The prompt uses a convention like
NO_REPLYso the user doesn’t see internal housekeeping.The runtime supports “silent housekeeping” turns and notes mitigations to reduce the chance of silent operations leaking via streaming when output begins with
NO_REPLY.
One more caveat that’s worth saying out loud:
If you sandbox the agent with read-only workspace access, the system can’t persist memory, and this invariant becomes impossible to enforce.
(You can still sandbox, just ensure the agent has a designated writable memory area.)
Part 2 kept the runtime sane under concurrency.
This part keeps it sane across time.
4) Rehydration is an API: search → get
Example: “What did we decide about travel dates?” shouldn’t force a full memory dump.
It should trigger a targeted lookup.
OpenClaw treats rehydration as an explicit tool pattern:
memory_searchfinds relevant snippets (discovery)memory_getreads the precise file / line range you actually need (retrieval)
This is “context hygiene as an API shape.” The tool boundary forces the runtime to stay surgical instead of stuffing entire files into the prompt “just in case.”
Here’s the core loop as a sequence diagram:
My take: once rehydration is tool-shaped, you can govern it: scoping, provenance, redaction, approvals. (That’s where Part 4 is headed.)
5) The index is derived state: retrieval + freshness knobs
If the memory files are the source of truth, the search index is derived state.
OpenClaw builds a per-agent index over memory files, watches for changes, debounces updates, and schedules sync so the index stays reasonably fresh without making chat feel sluggish.
Retrieval-wise, OpenClaw supports hybrid search:
vector similarity for “this means the same thing”
BM25 keyword relevance for exact tokens (IDs, symbols, env vars, error strings)
Hybrid matters because real systems contain both:
fuzzy intent (“speed up the pipeline”)
and exact strings (“ERR_CONNECTION_RESET”, “useFooBar()”, “ticket-1427”)
After the merge, OpenClaw exposes optional post-processing knobs that matter once you have real history:
Temporal decay to boost recency (stale memories shouldn’t dominate forever)
MMR re-ranking to increase diversity (avoid returning five near-duplicates)
This is the theme of the whole post: continuity comes from enforced invariants, not from hoping the model “keeps it in mind.”
6) If you remember one picture, make it this
The memory system is not a blob you shove into the prompt. It’s a loop between a durable store and an explicit rehydration interface.
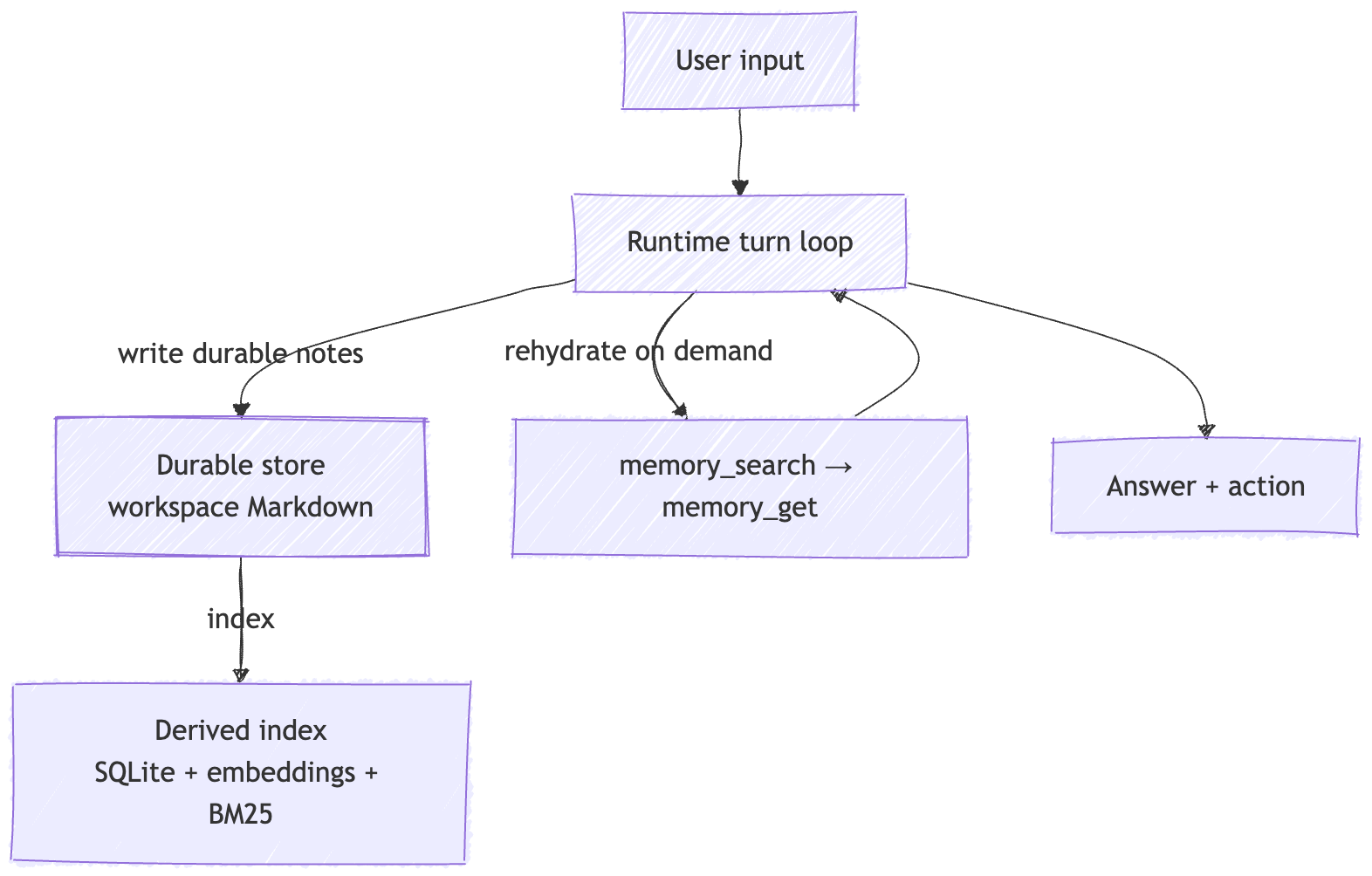
That’s the architecture you can reason about at 3:00 AM:
What got written?
Where?
When did we rehydrate?
From which scope?
And which invariant failed?
Failure modes
These are the ways memory systems get haunted (almost always because an invariant was violated):
Nothing durable was ever written
The agent acknowledged the fact, but nobody committed it to memory files.
Result: later runs have nothing to rehydrate.Compaction ate the only copy
The decision existed only in raw session context; compaction summarized and the detail vanished.
Mitigation: enforce the invariant — flush before discard.Context bloat / retrieval noise
You inject too much memory “always-on,” and the model gets slower, more expensive, and less reliable.
Mitigation: keep recall behind search → get.Stale or redundant retrieval
The index lags, or retrieval returns near-duplicates that crowd out useful variety.
Mitigation: watcher + sync discipline, then apply diversity/recency knobs when history grows.Memory poisoning becomes durable
If untrusted text can be written into durable memory, you’ve turned prompt injection into persistence.
Mitigation (teaser): treat memory writes like a privileged API: provenance, sanitization, and scoped write policies.
My take: writes are more dangerous than reads. Reads can leak. Writes can corrupt the future.
Builder checklist
If you’re building an OpenClaw-like memory system (or hardening one), here’s the checklist I’d actually use:
Define state ownership: session log vs durable memory vs external DBs.
Choose a durable source of truth you can diff/audit/migrate (files or a DB with proper logs).
Enforce the invariant: flush before discard (pre-compaction write-ahead checkpoint).
Make rehydration explicit: search → get, not “dump everything into context.”
Treat the index as derived state: rebuildable, refreshable, allowed to lag slightly without breaking correctness.
Use hybrid retrieval if you have identifiers (tickets, code, error strings).
Add cheap post-processing once history grows: recency + diversity.
Treat memory writes as privileged (scope + provenance + policy), not just another tool call.
Recap + Part 4 teaser
Memory isn’t learning.
It’s durable state + ownership + explicit rehydration.
OpenClaw stays sane across time because it enforces one critical invariant:
before we discard context, we persist what must survive.
Next in Part 4: memory becomes an attack surface - tool boundaries, authorization scopes, and why the control plane is the risk.
OpenClaw Architecture Series


Full series index + future parts will live on The Agent Stack:
References
 | A guest post by
|
The flush-before-discard invariant is the most important pattern here and the most under-discussed in agent memory generally. Most frameworks treat pre-compaction as cleanup. It's actually the highest-stakes moment in the system's cognitive life — the last chance to write what matters before it's gone.
One thing I'd push on: this framework treats decay as a post-processing knob — temporal recency, diversity scoring. But decay might be more fundamental than that. A system that retains everything without decay doesn't run out of space — it runs out of salience. When nothing is allowed to become less important, nothing is important. We've been experimenting with temporal decay in scoring: content that hasn't been attended to gradually recedes, so what the system surfaces reflects what matters now, not what mattered six weeks ago.
Is there room for a third retrieval layer? Vector catches ambient similarity. Keywords catch exact matches. Neither catches relationships that exist because someone exercised judgment about how things relate, not because they share vocabulary or mathematical proximity.
We need memory for all agents, and what if they shared memory with each other through cognitive meshes? Then what if they shared knowledge across the planet? I have a solution :) It’s the Nooplex.