
OpenClaw Architecture - Part 6: Reliability, Observability, and Evaluation
Why demos aren’t guarantees, and why it’s really just evidence + recovery + evaluation

Most demos look fine until the first ambiguous incident.
The agent says it sent the message.
The user says nothing arrived.
That is where production starts.
This post is really about what makes an agent stack survivable after that moment. Not whether the model looked clever in a happy path. The real question is whether the Gateway / Control plane leaves enough evidence, enforces enough invariants, and gives operators enough recovery paths to run the system without guessing.
What changes in production
A demo proves possibility.
It shows that the Runtime / Data plane can take a turn, call tools, and produce a result. Production asks a harder question: what still holds when the timing gets messy?
OpenClaw is useful here because its public docs describe the agent loop in concrete systems terms: intake, context assembly, model inference, tool execution, streaming replies, persistence. Once you look at the runtime that way, the production questions stop sounding mystical. They become questions about routing, ordering, retries, state ownership, and evidence.
If you remember one picture from this post, make it this one:
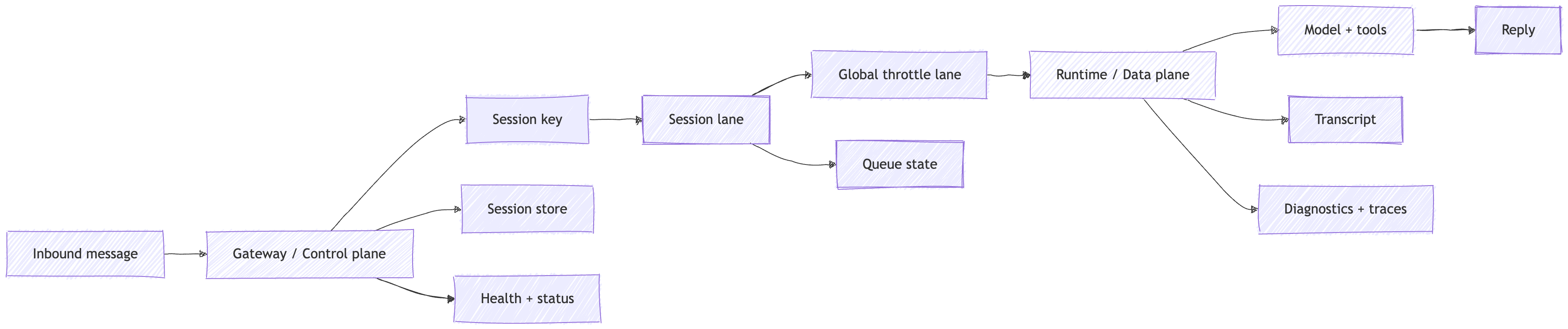
the production shape of an agent run - routed by session, serialized by lane, bounded by global concurrency, and backed by durable evidence.
A production agent is not the one that acted once. It is the one that left enough evidence for an operator to explain the action later.
That is the real shift.
In production, you care about duplicate delivery after reconnects. You care about whether two inputs can touch the same session at once. You care about whether the Gateway can still tell you what happened after a restart. You care about whether one shared agent quietly became one shared permission set.
A demo can ignore those questions for a while.
A real system cannot.
Reliability is mostly control-plane work
Two details are easy to gloss over.
First, the Session key is not a naming detail. It is the isolation boundary.
Second, the Lane/session lane is not just a queue implementation detail. It is the single-writer invariant.
OpenClaw’s queue docs make that pretty plain. The default lane is process-wide. agents.defaults.maxConcurrent opens parallelism across sessions. In this series, I treat that process-wide cap as the Global throttle lane. It is the host-level backpressure control. Additional lanes like cron and subagent let background work run without blocking the main reply path. But inside a session, the guarantee stays simple: one active run at a time.
That sounds like plumbing. It is.
It is also a lot of the sanity.
The same control-plane shape shows up at ingress and delivery boundaries. Channels can redeliver the same message after reconnects, so OpenClaw keeps a short-lived inbound dedupe cache. Conversations can get a burst of short messages, so OpenClaw can debounce them into one turn instead of three. The retry policy follows the same pattern: retry the current HTTP request, not the whole multi-step flow, so completed non-idempotent steps do not get repeated.
My read is that this is the real production lesson.
When people say an agent feels unstable, they usually mean one of two things. Either the model guessed badly, or the surrounding system failed to enforce an invariant. OpenClaw is a useful case study because it gives you a way to reason about the second category in plain systems language: serialization, backpressure, dedupe, debounce, and narrow retries.
Observability is how you prove what happened
A transcript is useful. It is not enough.
It tells you what the model saw and said. It does not tell you whether the run waited in a lane, whether a duplicate inbound message was dropped, whether the Gateway had already restarted once that hour, or whether the reply ever made it cleanly back through the channel.
What the operator can check right now
OpenClaw’s operator-facing surfaces are the boring ones you actually want in a real incident: openclaw status, openclaw gateway status, openclaw health, openclaw logs --follow, openclaw doctor, and openclaw channels status --probe. The Gateway is also the source of truth for session state, which matters when clients disagree about what happened.
Those are not “nice to have” tools.
They are how you stop guessing.
What the system can export over time
OpenClaw’s logging and diagnostics story is the longer-lived version of the same idea. The Gateway writes JSONL file logs, the Control UI can tail that log stream, and the logging docs describe diagnostics export with queue depth and wait, run duration, context size, token usage, cost, and message-processing spans.
That is the evidence surface.
My read is that a production run should leave behind more than a transcript. It should leave a small proof bundle: the triggering intent, the capability surface exposed for that run, any approval or denial events, and the durable record of side effects afterward. Without that, audits stay narrative when they should be verifiable.
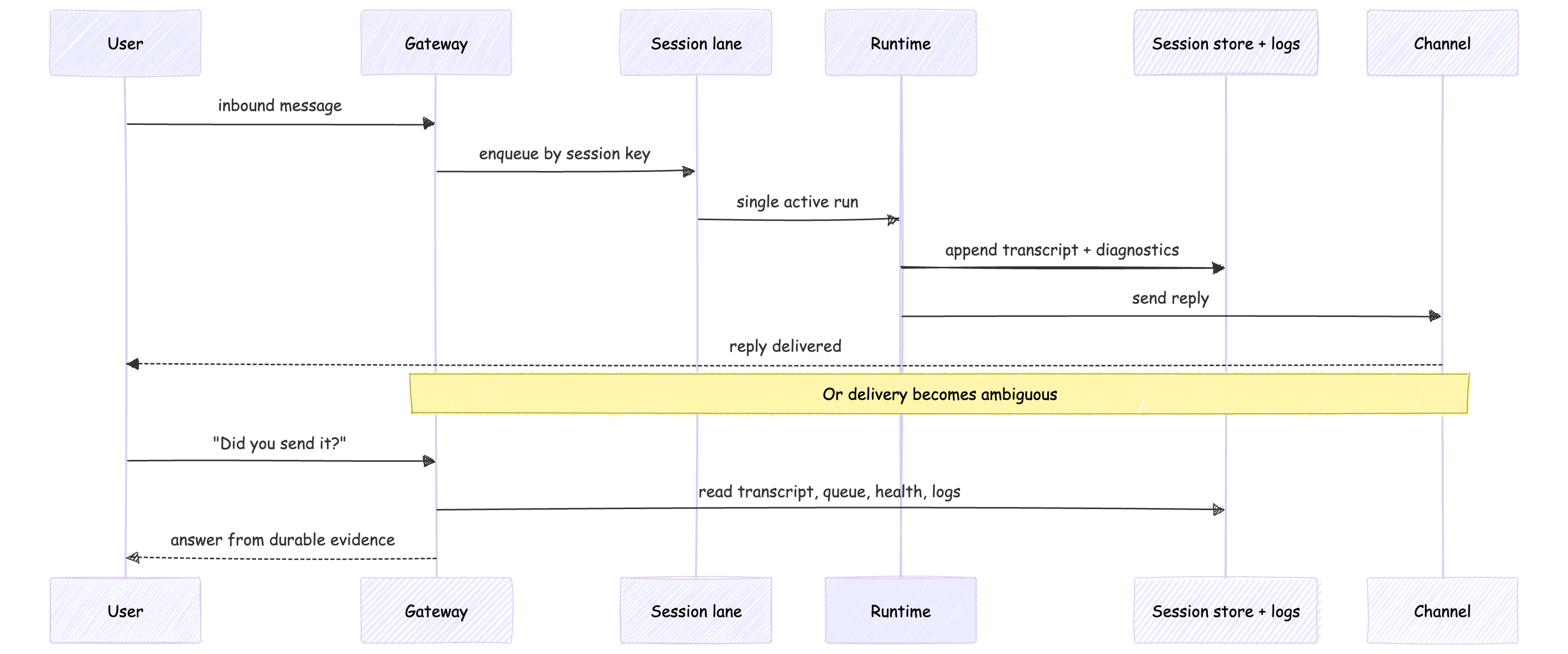
When a run becomes ambiguous, the operator needs durable evidence: transcript, queue state, health, and logs.
Observability is not a dashboard category. It is how you prove what happened.
At 3:00 AM, that is the only definition that really matters.
Recovery is different from replay
OpenClaw’s recovery story is strong when you describe it precisely.
The Gateway owns session state. Sessions are persisted in a store, and transcripts live as JSONL on the gateway host. Memory is plain Markdown in the workspace, and the files are the source of truth. If something matters later, it has to be written somewhere durable.
Replay is a stronger claim.
The Gateway docs explicitly say events are not replayed on sequence gaps. On a gap, clients refresh state and continue. That is a good line to keep sharp, because it forces a cleaner mental model. Recover from durable artifacts. Do not pretend the system can time-travel through every transient event that crossed the wire.
The same logic extends one layer outward when the agent acts on behalf of someone else. Then audit trail and containment start to matter in the same way. OpenClaw’s delegate docs explicitly call out cron run history, session transcripts, and identity-provider audit logs. Its security docs are equally clear that per-user session or memory isolation helps privacy, but does not turn a shared tool-enabled agent into per-user host authorization. For multi-user DMs, secure DM mode matters. For harder trust boundaries, separate gateways, OS users, or hosts matter.
A survivable system keeps two promises.
Incidents stay explainable.
Incidents stay small.
Recovery is not replay. A production system should recover from durable artifacts, not pretend it can reconstruct every transient event.
Evaluation closes the loop
OpenClaw’s own testing docs already have the right base shape: unit and integration, end-to-end, and live suites, plus guidance for adding regressions around real-world issues. That is a serious testing posture.
It is still not the full answer to behavioral quality in production.
Observability tells you what happened on one run.
Evaluation tells you whether the same class of behavior is repeating across runs, whether it is getting better, and whether a change actually improved the system or just looked good in a demo.
That distinction matters more for agents than for simpler LLM wrappers. Anthropic’s eval write-up makes the key point cleanly: for an agent, the outcome is often the final state of the environment, not whether the transcript sounded convincing in the middle. A tool-using system can narrate success and still fail the real task.
My read is that builders need two loops.
One is offline. Take the weird runs, the edge cases, the incidents, and the known bad behaviors. Turn them into a regression set.
The other is online. Sample real traces, review them, and feed the failures back into the offline set.
That is how you stop arguing from anecdotes.
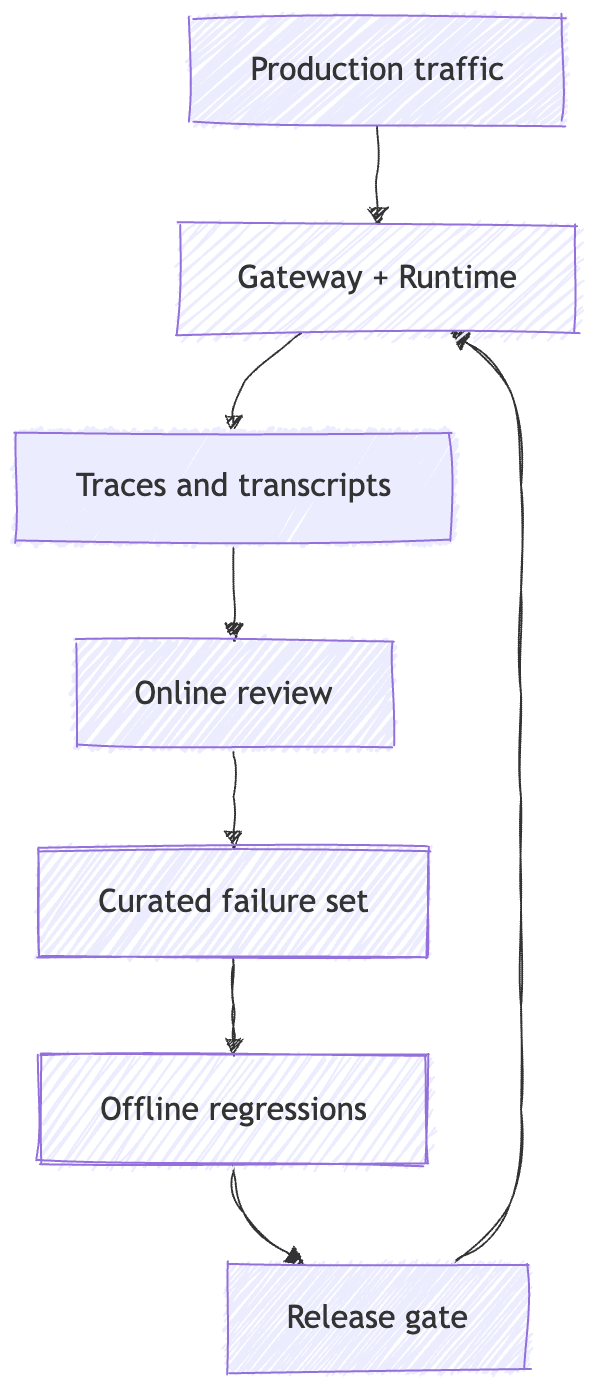
Production evaluation closes the loop by turning weird runs into traces, traces into regressions, and regressions into better releases.
A demo gives you one story. Evaluation tells you whether the story repeats.
That loop is also how you separate model quality from system quality.
If one input became two runs, or a retry duplicated a side effect, that is not the model being weird. That is transport or control-plane behavior. If the run happened once, the evidence is clean, and the result is still bad, then you are looking at model quality, prompting, tool choice, or context assembly instead.
Failure modes worth caring about
1. Telegram reconnect redelivers the same message. One user intent becomes two runs.
That is not a reasoning failure. It is an ingress and idempotency problem.
2. Message send succeeded, media upload failed, and the wrong retry level replayed the whole flow.
That is how you turn one partial transport error into a duplicate side effect.
3. The transcript looks clean, but the real problem was queue delay, a restart, or a sequence gap.
Without the rest of the evidence surface, the operator blames the model for a transport problem.
4. Several people can talk to one tool-enabled agent, and everyone is now steering the same permission set.
Session isolation helps privacy, but it does not reduce shared authority.
5. The team shipped from anecdotes. Nobody turned failures into regressions. The same class of mistake comes back a week later wearing different clothes.
That is not bad luck. That is an evaluation gap.
Builder checklist
If I were hardening an OpenClaw-style system for real use, these are the controls I would actually care about:
Make the Session key explicit and stable.
Enforce a single-writer session lane.
Cap overall concurrency with a Global throttle lane.
Treat transcript, logs, diagnostics, and health as one evidence surface.
Be honest about recovery. Rehydrate from durable artifacts; do not pretend you have perfect replay if you do not.
Keep an offline regression set and an online review loop.
Keep blast radius small with trust-boundary separation, secure DM mode where needed, and tight tool policy.
Remember that Memory is still state ownership. If it matters, write it to disk deliberately.
Recap
Agents are not trustworthy by default.
What makes them trustworthy in production is bounded behavior and durable evidence. The Gateway / Control plane has to enforce invariants. The Runtime / Data plane has to leave a trail. Operators need logs, health, transcripts, and recovery paths. Builders need evaluation that turns incidents into repeatable tests.
By this point in the series, the pattern is pretty plain.
Events wake the system.
The session key isolates it.
The session lane keeps it sane.
The global throttle lane keeps it bounded.
Tools give it reach.
Audit, recovery, and evaluation make it operable.
Once you stop treating agents like magic and start treating them like stateful, event-driven systems with boundaries, the questions get better.
Not “is it autonomous?”
What woke it?
What state did it touch?
What invariant bounded it?
What evidence survived after it acted?
That is a much less mystical picture.
It is also more useful.
What comes next
This wraps the OpenClaw Architecture series.
In the next series, I’m going to zoom out from one framework and map the layers of the modern agent stack: control planes, session ownership, runtimes, memory, tools, capability boundaries, execution surfaces, and production feedback loops.
The goal is to define a clearer systems model for how agent infrastructure is actually being built, then go layer by layer through the design patterns that keep these systems sane in production.
If there is a specific layer you want me to go deeper on, let me know in the comments.
OpenClaw Architecture Series
If you’re building agents and want systems-level explanations instead of demos and hype, subscribe to The Agent Stack.
This essay is part of the OpenClaw Architecture series on The Agent Stack. Start with Part 1, or browse the full series archive.
References / further reading
Session Management, Messages, Command Queue, Retry Policy, and Agent Loop - session ownership, inbound routing, dedupe/debounce, serialization, retry boundaries, and the runtime path from intake to action.
Gateway Runbook, Gateway Architecture, Gateway Troubleshooting, FAQ, and Logging - health, status, diagnostics, gap recovery, operator commands, and longer-lived telemetry.
Testing - layered suites, live tests, and regression posture.
Delegate Architecture and Security - audit trail, secure DM mode, trust boundaries, and containment.
Demystifying evals for AI agents - secondary framing for outcome-based evaluation versus transcript-only judgment.